At some point a cloud bill lands where the database has outgrown every other service on it. The question, usually from finance, is whether engineering has it under control.
In most cases the team has known about it for months. The bill isn’t the first sign of a problem; it’s just the most visible one.
I’ve worked on three systems where this conversation eventually came up. The first was a high-volume consumer platform where any database problem showed up immediately as customer impact. The second was an internal enterprise system with predictable load and an internal user base that could tolerate a degraded window. The third was a public, event-driven platform with spiky and unpredictable demand around peak events. Different shapes, different constraints. The path of least resistance is always the same: scale up the database.
The upgrade works. The architectural conversation it postpones is the one that compounds. So do the hidden costs: slower releases, longer incidents, deferred features, slow service at peak.
By the Time Finance Asks
When the invoice raises a question, engineering has usually been dealing with the symptoms for months. Some queries have been running slowly, and the warnings get acknowledged and forgotten. With each release, user requests wait a little longer for their turn at the database. Software updates run late because the database can’t take a structural change on top of the existing load. When something goes wrong, the database is already overloaded by the time the team is paged, so the outage runs longer than it should.
None of this shows up on the cloud bill. It shows up as engineer hours, feature work pushed to the next quarter, and post-incident reviews that keep pointing at the database without resolving anything. Finance sees the dollar figure. The team has been paying for it in time, long before it became a number on a slide.
The ratio varies by system, but a typical SaaS sits around 30% of the hosting bill. Above 40%, the architectural conversation is overdue.
The Instinct: Throw More Database at It
The reflex is to scale the database: more CPU, more memory, a bigger server tier, a read replica or two. It works. Dashboards recover, latency drops, the next release goes smoothly, and the team moves on.
Then the next peak arrives, and the cycle repeats.
On the public event-driven platform, this loop ran for years. Each peak event drove the database to its limits, the response was a bigger instance, the bill rose between events, and the cycle repeated at the next fixture.
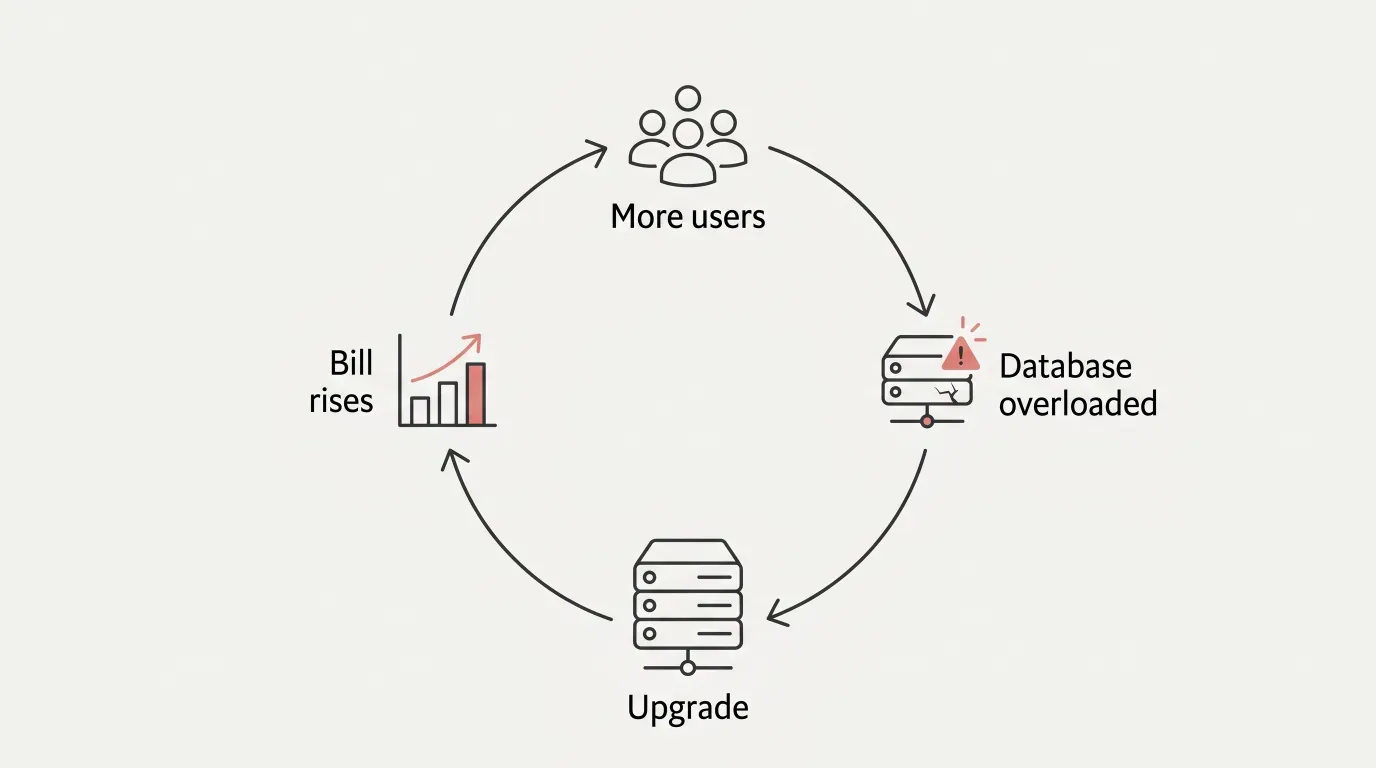
This loop is a sign of an architecture that assumed more than it understood about the application it had to serve, now compensating with hardware for the assumptions that didn’t hold. Each upgrade buys time. None address the underlying design. And because cloud spend is operating expense rather than capital investment, no decision is ever formally made: the bill rises and the architecture stays put.
Reads and Writes Are Not the Same Workload
For most user-facing applications, reads outnumber writes by ten to a hundred times. Content sites and dashboards skew higher; messaging, IoT, and real-time analytics tend to be the opposite. But for the typical product, the pattern holds: the same data is read many times before anyone changes it.
The mistake is sending both through the same path. Reads, at scale, are cheap to serve from a cache. Writes are the bottleneck. Each one has to commit safely to disk, hold a lock, and update every index. When the two share the same path, slow writes hold up the reads waiting behind them. The queue in front of the database fills up before the database itself runs out of capacity.
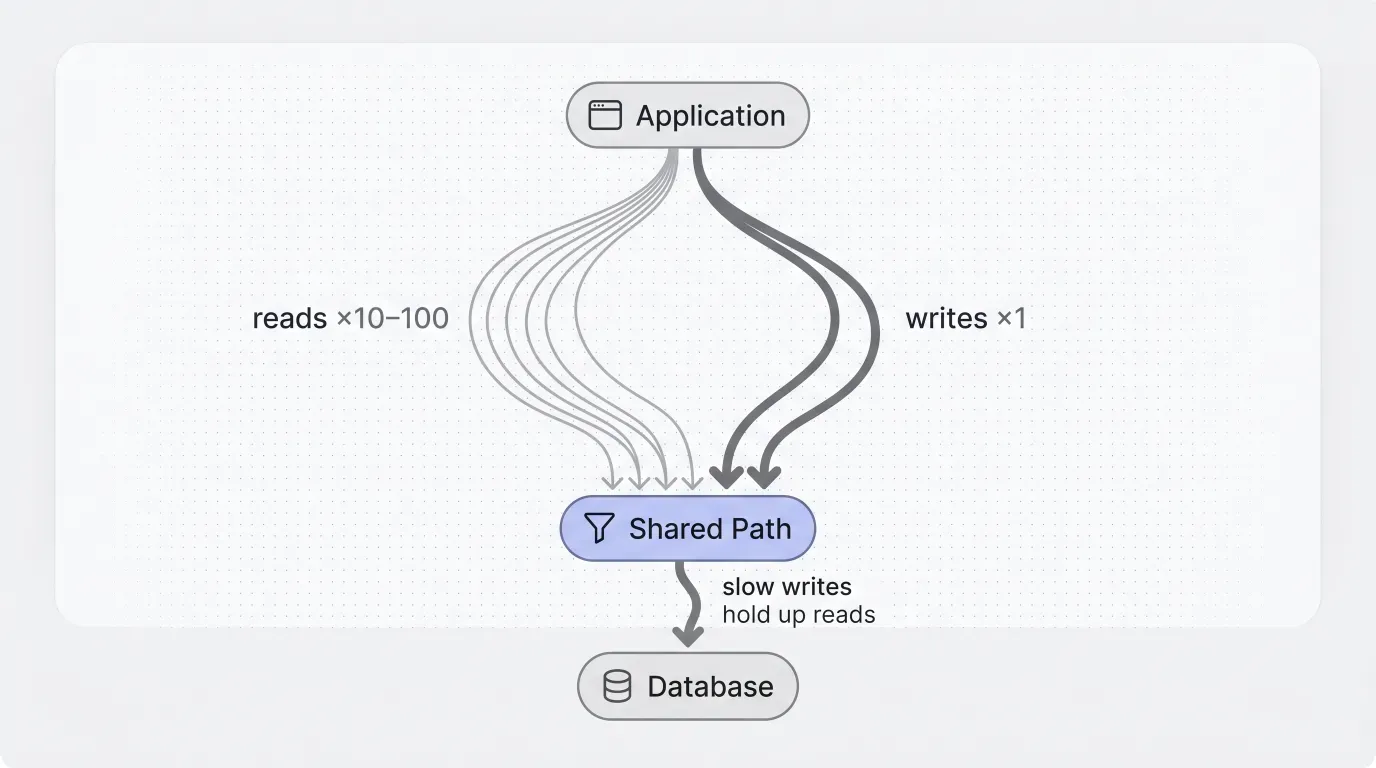
Reads aren’t one thing either. Different patterns call for different caching strategies: frequently versus rarely accessed, personal versus shared. A single cache, applied indiscriminately, becomes its own source of bugs.
Step Zero: Diagnose Before You Re-architect
Before reaching for queues and caches, exhaust the cheap fixes. Skipping them often produces a re-architecture that didn’t address the bottleneck and a longer migration than necessary.
Most of the candidates are unglamorous: missing indexes, code that quietly issues hundreds of small database calls when one would do, queries that return more data than they need, and connection limits set to the wrong number for the actual load. None of these are interesting. All of them buy real headroom before anything architectural is needed.
Underneath all of these is the discipline of measuring first. Without baseline numbers on which queries are slow, which are frequent, and where the system spends its time waiting, it’s impossible to tell which change actually helped. The bill drops after a rewrite, but it isn’t clear whether the queue or the index did the work.
At one organisation we were convinced an event-day spike was a fundamental architecture problem. It turned out a missing index on a frequently-run query was responsible for most of the saturation. The architectural work was still worth doing, but the index bought us time to do it properly rather than under incident pressure.
The Re-architecture: Queue, Cache, Don’t Expose
The pattern doesn’t apply equally to every system. A consumer platform with sustained external traffic needs the full version, because any slowdown is customer-visible. An internal system with predictable load usually doesn’t; a slow day stays inside. A public platform with spiky peaks needs it at peak, and the harder question is whether to maintain it between peaks.
Once the cheap fixes are exhausted and the load is genuinely architectural, three levers apply.
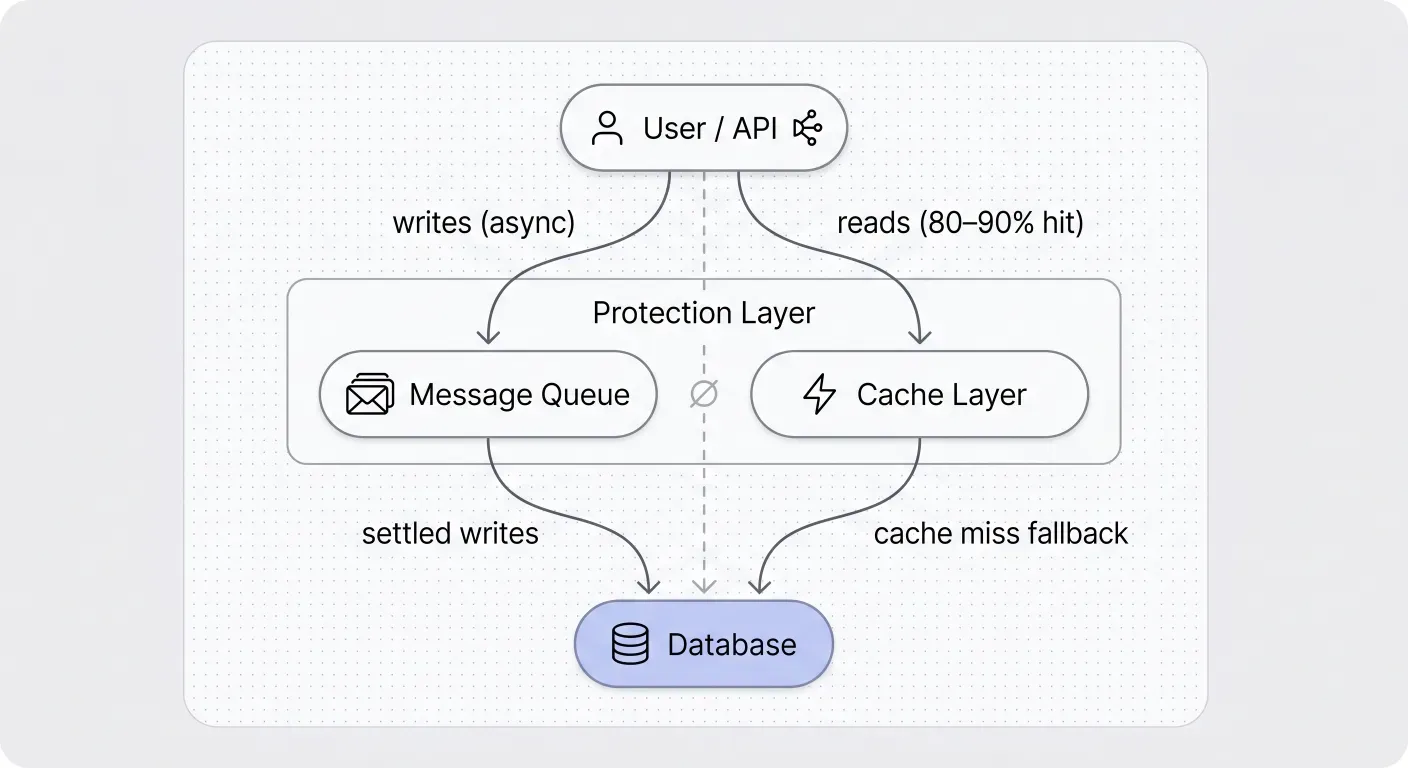
Queue writes. Don’t let the user interface write directly to the database. Updates go through a message queue and are processed asynchronously. The database is no longer in the middle of every user action: the queue absorbs the spike and the database works at its own rate. The cost is eventual consistency on write paths, addressed below. Writes also have to be safe to retry, because queues redeliver under failure.
Cache reads. Most read traffic can be served from a cache. The database remains the source of truth; the cache absorbs the load. Hit rates of 80% to 90% are typical on read-heavy surfaces, and static sites can reach 100%.
Don’t expose the database directly. No user-facing operation, no public API call, should reach the database without going through a layer that handles the queue and cache. Every direct path is a risk: a place where load can leak through, or where one bad request can take down more than it should.
The high-volume consumer platform from earlier was built this way from the start: writes flowed through a message queue, reads were served from a cache layer, and the database sat behind both rather than in front of every user action. It absorbed load that would have collapsed a more conventional setup, and the cost conversation that drove this piece never landed on its desk.
In practice the migration is incremental. Pick the highest-write endpoint, queue that, then cache the highest-read query waiting behind it, and let the load profile guide the next move. The infrastructure built for the first endpoint serves the next; the bill drops before the system is fully re-architected.
This is the practical form of CQRS (Command Query Responsibility Segregation), separating reads from writes by path and timing. Strict CQRS goes further, with distinct data models on each side, which is more than most teams need. Old idea, newly accessible: managed queues, hosted caches, and edge networks make it reachable for teams that, twenty years ago, would have had to build it from scratch.
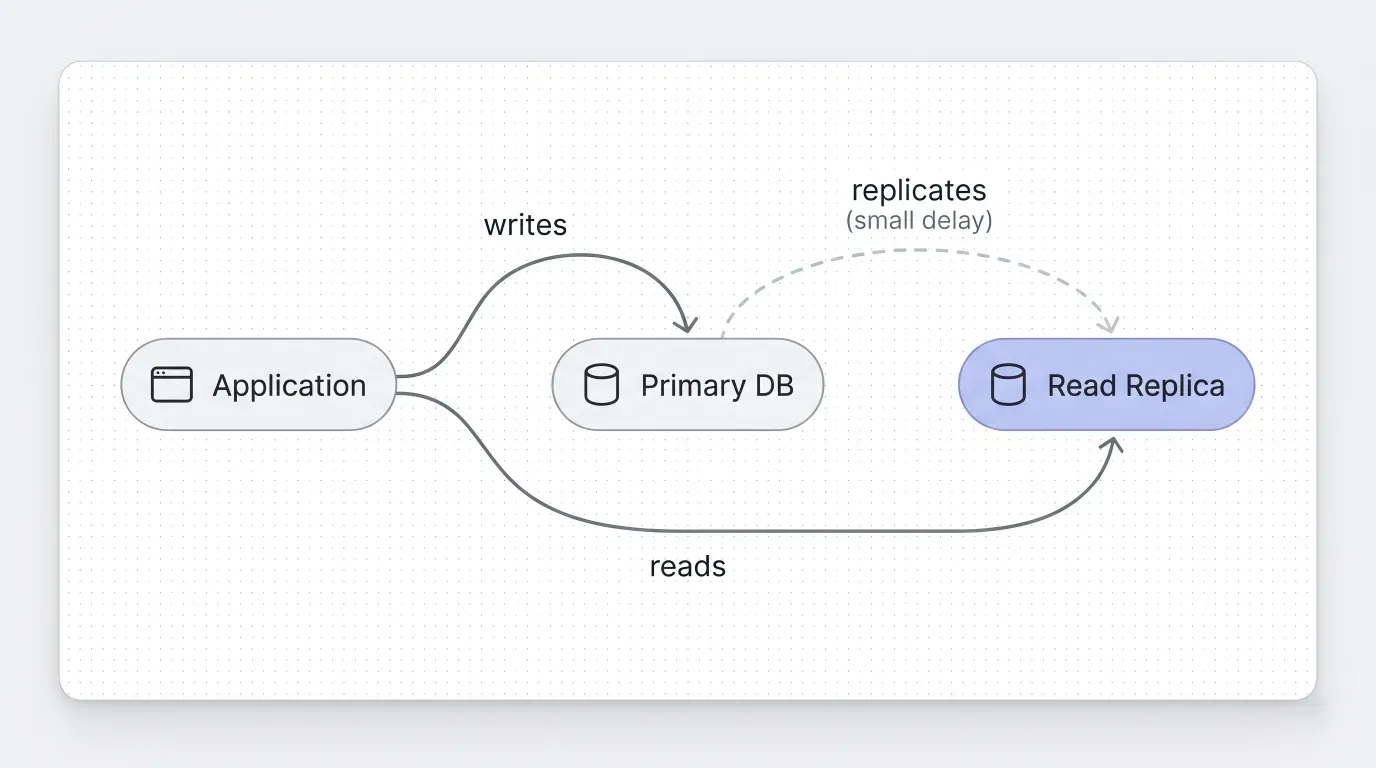
The Middle Ground Worth Knowing: Read Replicas
Between “do nothing” and a full re-architecture sits the read replica. A replica reduces pressure on the main database with minimal architectural change: point read traffic at the replica, accept that the copy catches up with a small delay, and the application gets real headroom without a rewrite.
For many systems this is the smallest viable move. It’s not architecturally interesting, which is partly why teams skip it. But the smallest viable move is usually the right answer when the alternative is a six-month rewrite.
The Bigger Shifts: Conceptual and Organisational
The technical change is the smaller part of the work. The harder shifts are conceptual and organisational.
Eventual consistency. Async writes mean data is correct but not always immediately current. That’s by design; the system catches up. How this is framed to stakeholders decides whether they accept it or fight it for the lifetime of the product.
The product conversation. The hardest meeting in this migration is with the product owner who wants to know why a form submission no longer shows immediate confirmation. Async writes change the user experience as much as the backend. Treating this as an engineering migration rather than a product redesign produces a system that meets the technical requirements but degrades the customer experience.
The customer-facing patterns. Once writes are asynchronous, the interface has to tell the user what state the system is in. Some forms need to show “your change is being processed” before the system has finished. Others need to lock controls so the user can’t submit the same action twice while the first is still in flight. Design and CX own this work; engineering supports it.
Customer support readiness. Customers will contact support when their action “isn’t there yet”. Support staff need internal tooling that shows queued versus settled state, training that explains what they’re seeing, and scripted responses for the common cases. Without this, every confused customer escalates to engineering, and the cost of the new pattern shows up in support ticket volume rather than infrastructure spend.
When This Is the Wrong Choice
The pattern is the wrong choice when strong consistency isn’t optional.
Payments are the obvious example: a payment that appears to succeed but doesn’t is a real-world problem, not a UX issue. Inventory is another: overselling from a stale cache is expensive and difficult to reverse at scale. Anything where a stale read drives a downstream real-world action falls in the same category: bookings, allocations, financial transactions.
For those surfaces, the trade-off flips: strong consistency and synchronous writes, accepting the cost. The discipline is being honest about which surfaces fall in which category. Most don’t need synchronous consistency, but where it matters, the cost of getting it wrong is significant.
For these surfaces, there’s a way to keep cost predictable: shape the demand at the front door. Virtual queues admit users to the system in controlled batches. Anyone who has tried to buy popular concert tickets has seen one. Excess demand sits in the waiting room rather than scaling the database. The system can be sized for the throughput it can handle, not the peak demand it receives.
Anti-Patterns: The Wrong Answers People Reach For
Each of these feels like progress, which is why they keep recurring.
| Proposal | Why it fails |
|---|---|
| ”Just add Redis.” | Without an invalidation strategy, staleness moves from the database to the cache. |
| ”Microservices will fix it.” | Splitting services without splitting write paths leaves the same shared database pretending to be decoupled. |
| ”We need NoSQL.” | The issue is access patterns and architecture, not the storage engine. The asymmetry follows the data into the new system unchanged. |
| ”Shard the database.” | Buys headroom at the cost of permanent operational complexity. Right tool for a problem most don’t have. |
Vertical scaling on autopilot. The anti-pattern no one proposes. The instance gets bigger each quarter, the bill grows, and no one calls it a choice. By the time finance raises the question, the same architectural decision has been ratified by inaction for two years.
The Leadership Job
This is where the conversation stops being purely technical and becomes the leadership job.
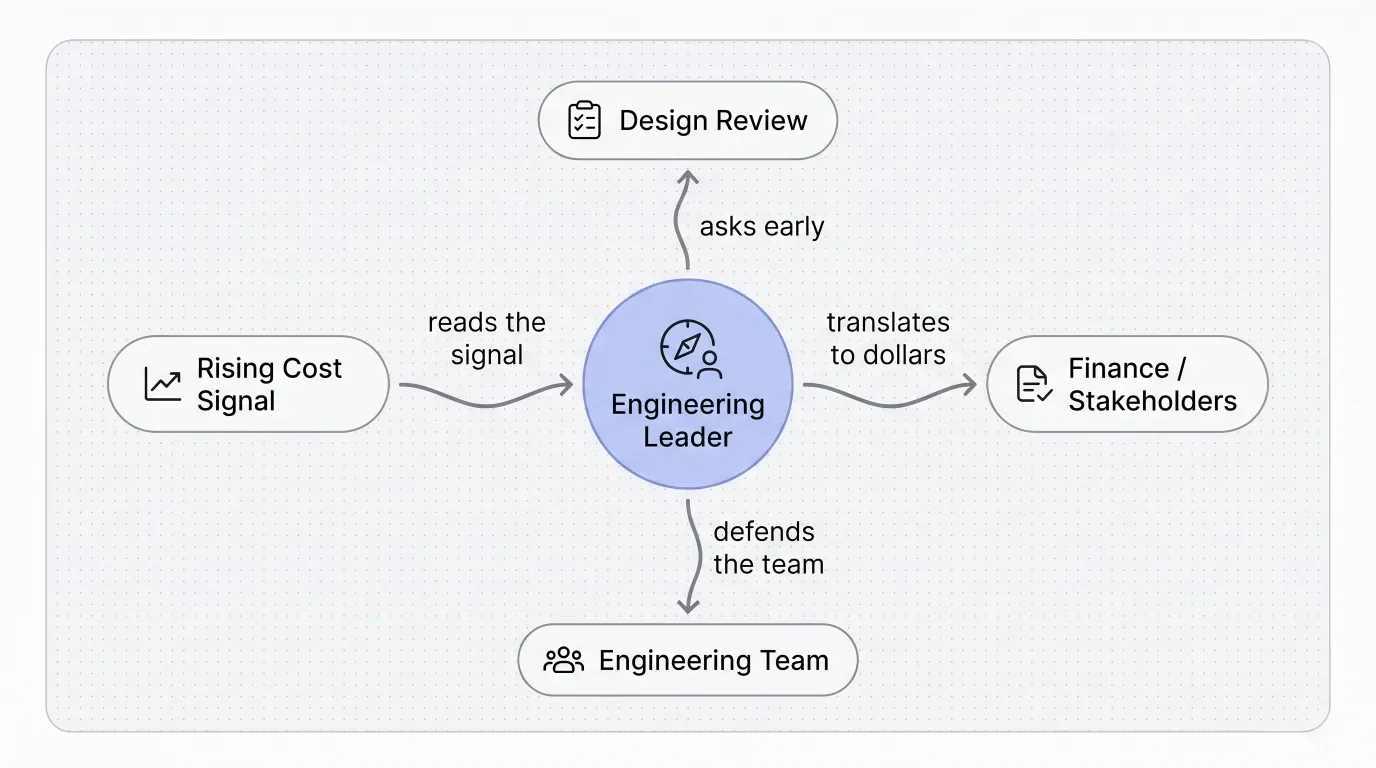
Cost as a forcing function. Cloud bills make architecture visible in dollars in a way on-prem never did. Finance turns into an ally for the conversation, because a projected cost curve is more persuasive than any technical diagram. The change that couldn’t get approval for two years gets signed off in one meeting once finance has that curve on a slide.
Reading the signal correctly. A rising database bill is often misread up the chain as “engineering inefficiency”. It is an architectural signal that the system has outgrown its original shape. Defending the team while owning the architecture is the job. Pretending otherwise burns trust with the team and with the executive who eventually finds out.
Communicating eventual consistency. “Eventual consistency” is jargon that loses non-technical stakeholders. Plainer framings work better: the system catches up, queued versus processed, in-flight versus settled, a confirmation arrives once it’s done. The vocabulary decides whether the room understands the trade-off or dismisses it as engineering opacity.
Knowing when not to invest in the rewrite. Not every system needs this pattern. The right answer depends on load profile, team maturity, and downtime tolerance. Sometimes good operational hygiene plus incremental fixes is the right call. Saying so directly, rather than reaching for the architecturally interesting solution, is the harder decision. I’ve been on both sides of this call. Neither error shows up immediately.
The internal enterprise system is the example. Internal users, predictable load, single system, tolerable degradation window: the full re-architecture would have been complexity for its own sake. Vertical scaling and discipline around indexes was the right answer. The high-volume consumer platform and the public event-driven system sit at the other end of the spectrum, where the pattern earns its complexity.
The questions to ask before the bill arrives. What is the read/write ratio of this surface? What happens at ten times current load? Is the database in the middle of every user action, and does it need to be? Asking these in design review is cheaper than answering them under incident pressure.
Designing for It from the Start
For systems being built fresh, or where architectural decisions can be made before scale forces them, the principle is straightforward: treat the database as the authoritative store of record, not the workhorse of every user action. Design for the read/write asymmetry from day one.
The pattern is not new. The ecosystem is mature, the tooling is accessible, and the trade-offs are understood. The teams that arrive here painfully are the ones who built fast without considering behaviour at ten times current load. The teams that arrive comfortably are the ones who asked the question early.
The same asymmetry appears wherever a hot path saturates. AI inference is the next version of this conversation, and for many teams the next cost spiral will be measured in tokens rather than database hours. The three moves transfer cleanly: queue long-running generations, cache prompts and embeddings, don’t expose the model to every user click. Embeddings cache like reads. Batched inference is the new asynchronous write. A smaller model for the cheap calls is the new “use the right tool for the load”. The pattern is not specific to databases; it’s a way of thinking about where the work happens.
Closing
The decision to re-architect along these lines is a leadership choice, not a technical one. The choice gets made deliberately, in design review, or implicitly, after an incident or a finance escalation. The hard part is organisational: whether the conversation happens while it’s still cheap.
Deferring costs more than the bill: releases slow, incidents stretch, features get pushed, customers feel it at peak.
The question is whether the conversation happens before the bill forces it.